Paper——Real-time 3D Reconstruction at Scale using Voxel Hashing
之前的两篇文章都使用了voxel hashing的策略,而实际上为了减少存储,一般不会将空间所有的voxel都记录下来,而是使用voxel hashing或者octree的方法。而这篇文章(Real-time 3D Reconstruction at Scale using Voxel Hashing)是最早使用voxel hashing的。它的引用量达到了390。鉴于不是深度学习等热门领域,实际上这个成绩已经相当不错了。
当然,这篇文章中使用的还是TSDF,对于TSDF我就不多介绍了。在之前的表示中,会存储每个voxel的TSDF值。但是既然使用了截断SDF值,意味着不在截断范围内的体素组成的空间是free space,也就是没有必要的部分,对表面的重建不会有太大的帮助。因此可以设计一个新的数据结构来开发有效体素的稀疏性。实际上在之前图形学领域中,已经有hashing算法提出用来进行2D/3D渲染阶段以及,在基于GPU的hashing中也提出了成熟的方法,极大减少了hash冲突的数量。
这篇文章提出的系统目标是建立一个实时系统,探索一种空间hashing的方案,来实现可伸缩(scalable)体积的重建。对于三维重建来说非常重要的是,因为要重建的目标几何形状是未知的,并且可能随着时间不断变化(指的是随着时间变化获取信息在增加,或者由于优化改变了之前的重建结果),所以提出的数据结构应该可以动态分配和更新,同时还要在不知道任何重建表面的先验信息的情况下最小化潜在的hash冲突。
这篇文章提出的数据结构有下面几个优点:
- 可以高效压缩TSDF,并且不降低分辨率,不适用分层的数据结构
- 可以高效地融合新的TSDF到哈希表中
- 无需重新组织结构就可以删除和收集无用的voxel block
- 在主机和GPU之间轻量级的voxel block双向流,允许无限制的重建
- 可以使用标准的raycasting或者多边形操作高效提取等值面(isosurface),用来进行渲染以及相机位姿估计
System Pipeline
这个系统的Pipeline非常简单,如下图:

这个系统最关键的部分是空间哈希的策略。将voxels组织成块(例如8×8×8),每个体素包含一个TSDF值,一个weight以及一个额外的颜色值(可选)。这个哈希表是unstructured,也就是不是根据空间位置顺序分配的,可能离得很近的block在哈希表的实际位置中距离很远。我们也不会按照空间位置来查找对应的block,而是根据一个能够极大减少冲突的hash映射。
当有新的深度图进来时,使用ICP算法对位姿进行估计(使用的是point-plane的ICP,来保证位姿估计是frame to model而不是frame to frame,从而减少了飘逸的情况),接着开始进行integration。首先根据相机视锥,对所有的voxel进行block的分配,然后对每一个voxel进行TSDF的计算。然后我们进行垃圾收集,找出所有voxel都在表面截断范围外的block,在hash表中删除。这个步骤保证了hash表的稀疏性。
在integration之后,根据进行raycast,从而得到表面。
Data Structure
想象将无穷的空间分割均匀分割成一个个block,每个block又分成N(8×8×8)个voxel。voxel的结构如下:
1 |
struct Voxel{ |
hash表与一般的hash表区别不大,也就是根据世界坐标位置\((x,y,z)\)通过哈希函数得到一个映射,找到block,从而找到voxel。hash函数如下:
H(x,y,z) = (xp_1 yp_2 z p_3)mod n
为了减少冲突,\(p_1,p_2,p_3\)是大质数(73856093, 19349669, 83492791),n是hash表的大小。除了存储一个指针指向voxel block,每个哈希entry也包含了世界坐标,一个偏移量,用来存储冲突发生时,相对于计算的位置的偏移量。
1 |
struct HashEntry{ |
整个哈希表结构如下图:
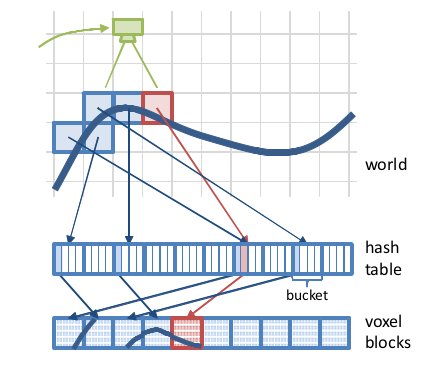
为了解决冲突,作者将hash entry指针指向一个bucket。bucket大小固定,通过顺序遍历bucket来找到对应的hash entry(比较position)。当bucket满了的时候,寻找临近的bucket来找到是否有空闲的位置,而这个bucket相对于原来的偏移量就是offset,被存储在链表上一个entry中。这是hash表的一个比较通用的实现方式。
下图为哈希表插入以及删除的一个过程:
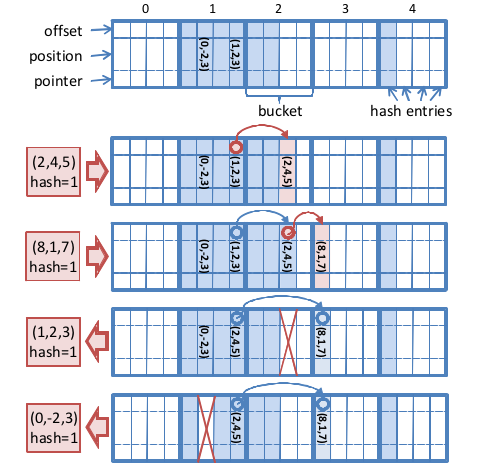
值得注意的是,为了实行链表这个操作,每个bucket最后一个entry只能放链表的表头,也就是本身就该分配到这个bucket的元素才能插入该bucket的最后一个位置。
在查找操作中,找到对应的bucket,然后遍历,如果到了结尾依然找不到,就顺着链表继续找,直到查找成功,或者遇到一个空位置,说明查找失败。
需要注意的是,在垃圾收集过程中,我们会用到遍历block中的voxel时候设定的weight最大值,或者sdf最小值。如果weight最大值小于0,或者最小sdf绝对值大于1(或者某个值),那么就将这个block看做invalid,最后被删除掉。
对于本篇文章的其他内容,基本算是老生常谈了。动态的truncation,用来补偿远距离深度的不确定性,根据ICP估计位姿,根据raycast,tri-linear interpolation来计算出表面。以及一些GPU和host的双向流,这目前还不是我关注的重点。
实际上,如果不用GPU,本篇文章的hashing scheme思想还是比较简单的。而现在这样的idea越来越少了,目前的reconstruction系统需要结合IMU,纹理贴图等等,变得越来越复杂庞大了。