Paper——RLSD 3D Reconstruction with LCD
这次介绍的论文是牛津大学的一篇文章,全文名为Real-time Large-Scale Dense 3D Reconstruction with Loop Closure。这是一篇16年ECCV的文章,我主要希望借鉴的是文章中关于submap的一些做法和想法。
和之前一样,我们跳过abstract,introduction,related work以及实验evaluation的部分,主要介绍这个系统的pipeline和技术实现。RLSD使用的是Submap的方法来重建,与之前的FlashFusion有较大的不同。不过在重建上,它依然使用的是hashing voxel与TSDF fusion。
融合深度图
融合深度图其实也就是TSDF过程。为了方便理解,我们就使用论文中的符号来讲解TSDF的过程。实际上这里的TSDF与之前的也没有什么不同,不过在这里再次详细说明一下。
我们把地图中的场景用TSDF来描述,而具体的值用一个函数\(F(X)\)来描述。其中\(X\)表示的是空间中的一个体素坐标,而\(F(X)\)则是一个三元组\((d,w,c)\),\(d\)表示sdf值,也就是\(X\)距离最近的表面的距离,\(w\)表示的是权重,\(c\)表示的是颜色,这个是可选的。当然,还有个截断范围\([-\mu,\mu]\),超出截断范围的,设\(w=0\),\(d,c\)为未定义(或者为1)。在本文中,\(8\times 8 \times 8\)为一个block,有效的block(包含了在截距范围内的voxel)才会被分配。为了找到一个空间点\(X\)对应的block,我们需要使用一个hash映射。这与FlashFusion中并没有太大的不同。
Tracking这一步是基于ICP算法的。众所周知,ICP算法是3D点之间的配准,而对于点的对应基于的是投影数据的联系,这个联系可以通过特征点匹配等等来得到。我们记相机内参为\(K\),\(t\)时刻的深度图为\(D_t\)(也就是相机坐标下的z值),这样可以得到一个从2D到3D的转换: \[ p(x) = D_t(x)K^{-1}\begin{pmatrix} x\\ 1 \end{pmatrix}. \]
上面式子不难理解,其实正是我们之前介绍过的内容。这里的\(x\)指的是像素坐标,二维,而\(P(x)\)也就是\(x\)对应的相机坐标。
在每个时刻\(t\),我们想估计的是位姿\(T_t = (R_t,t_t)\),其中\(R_t\)表示旋转,而\(t_t\)表示的是平移。作为额外的输入,我们需要知道的是一个2D对应的3D的地图\(V_{t-1}(x)\),以及表面法向图\(N_{t-1}(x)\),这些都可以从已知位姿\(T_{t-1}\)以及TSDF中得到,我们通过使得下面的代价函数最小化来计算\(T_t\): \[ \epsilon_{ICP} (T_t) = \sum_x \rho\left((T_t^{-1}P(x) - V_{t-1}(\overline P(x)))^T N_{t-1}(\overline P(x))\right) \]
上式中,\(\rho\)是一个鲁棒的错误范数(比如huber),而\(\overline P(x) = \pi(KT_{t-1}T_t^{-1}P(x))\)。上式看起来比较复杂,但是细心分解一下还是不难理解的。\(\pi\)表示从齐次到非齐次的转换,也就是取前两维,使得三维变为二维坐标。\(\overline P(x)\)求的是\(x\)对应的点在\(t-1\)时刻的相机下的2维投影位置。而\(V_{t-1}(x)\)得到了\(t-1\)时刻像素位置\(x\)对应的三维点坐标,这个坐标是世界坐标系下的坐标。因此,\(T_t^{-1}P(x) - V_{t-1}(\overline P(x))\)理论应该是为0的,也就是我们需要优化的部分。而乘上法向量的部分我就不是很明白了,不知道有什么优点。论文中通过列文伯格-马夸尔特法来求得极值点。
为了将深度\(D_t\)融合到TSDF中,对于空间点集\(\{T_t^{-1}P(x)\}\)以及在它们截断距离内的点,我们在Hash表中分配对应的voxel block,并且将它们设定为可见集合\(\mathbb{V}\)的一部分。然后我们对可见集合中所有的voxel进行下面的更新: \[ d \leftarrow \frac{wd+d^*}{w+1},c\leftarrow \frac{wc + c^ *}{w+1}, w\leftarrow w+1, \]
上式中,\(d^\* = D_t(\pi(KT_tX)) - [T_tX]_{(z)}\),也就是一个空间点投影到像素位置后,用该位置的深度减去该空间点的z值,从而得到了该点到表面的距离。如果颜色也是可用的,那么\(c^\* = C_t(\pi (KT_tX))\),也就是简单的取了投影像素位置的颜色值。
对于当前时刻的\(V,N\)地图我们可以通过raycasting来获得。关于raycasting论文中介绍的不多,和TSDF中的差距也不大。
Tracking准确率的评估
这篇文章中一个创新的地方是利用SVM对tracking是否成功进行评估。大多数现有的系统对于tracking失败的问题都不会做特殊的处理,但是在本文中,知道tracking是否失败对于建立一个鲁棒的建图系统以及建立submap之间的constraint都非常关键。
一般来说对于tracking是否失败的检测,会手动设定一个阈值,然后根据tracking过程中得到的指标来判断。这有一些额外的要求,比如residual不应该比某个阈值更大。而在本篇文章中,作者训练一个分类器来分开tracking成功与tracking失败的情况。对于每个\(\epsilon_{ICP}\)的优化,衡量inlier的百分比,Hessian矩阵的行列式以及最后的residual。接着,使用一个\(x^2\)的kernel函数将这三个特征推展为20维的描述子。最后,使用SVM来进行tracking成功和tracking失败进行分类。这个训练过程是在7 scenes数据集上进行的,从而获得需要的参数。通过训练,分类器分类的正确率达到95%,如果不使用kernel,成功率会下降到92.4%。具体的训练细节在这里就不多说了,我们主要是关注这个paper中的思想。
Submap的构造
本篇paper和FlashFusion最大的不同是使用了submap,submap的好处是每个小图的维护比较精确,而全局的优化也可以简化成对于各个submap位姿的优化,而不是对于每个关键帧都进行优化。因此可以减少计算量,从而实现对large scale的重建。这里先了解一下submap的构建。
在之前的工作中,submap建立的策略有两种,一是每\(k\)帧建立一个submap,在这种情况下,submap增长的速度是和时间成正比的,而各个submap之间的相似度取决于相机移动的速度。比如如果相机移动过慢或者静止,多个submap的内容可能一样,另外一种是根据相机的移动来建立submap。这样如果相机不动,就不会建立新的submap。
本文中提出了一种新颖的策略:我们评估这个场景的可见度,并且当相机的视窗移开了之前submap的中心位置,就开始一个新的submap。
Voxel hashing的方法很适合这个策略。我们给场景中新的部分分配voxel block。此外,我们维持了一个可见块集合\(\mathbb V\)。因为之前分配的block更有可能在submap的附近,我们计算可见块\(\mathbb V\)中的一个比例\(r_{vis}\)。这个比例指的是block creation index小于某个阈值\(B\)的比例。这么想,新建的block的creation index是越来越大的,因此,如果新建的block越多,那么有较小的index的block占的比例\(r_{vis}\)就会变小。如果\(r_{vis}< \theta\),则说明相机的视窗移动过去了,我们就开始一个新的submap。而\(\theta\)与\(B\)的值决定了每个submap的大小。
Submap之间的constraints
在之前的关于submap的论文中,一个基本观点是local submaps需要能够互相重叠。本篇文章和这些之前工作不同的地方在于,我们同时并行多个submap的建立,由于高效的voxel block hashing,这种并行是可以实时进行的。
当我们假设submap之间一个新的overlap时,我们会跑一个额外独立的进程来建图。在尽可能多的submap上tracking,在全局帧中,相机的轨迹应该是一样的。这就给了我们在这些submap之间的constraint。在时间\(t\)从submap \(i\)到submap \(j\)的转换为\(T_{t,i,j}\),则: \[ T_{t,i,j} = T_{t,j}^{-1}T_{t,i}, \] 上式中\(T_{t,j},T_{t,i}\)分别是submap \(i,j\)中tracking得到的位姿。
当我们tracking成功的时候,我们得到最高品质的有效constraint:\(T_{t,i,j}\)。为了维持一致性,多个这样的constraint被累加到一起得到一个总体的估计\(T_{i,j}\)。我们认为\(v(T)\)是一个压缩的6维向量来代表位姿的转换\(T\),计算: \[ v(\hat T_{i,j}) = \sum_{t}w_t v(T_{t,i,j}) + wv(T_{i,j})\sum_{t} w_t + w, \]
上式中\(w_t = \frac{\sqrt{2b\hat r - b^2} }{\hat r}, r = \max(\Vert v(T_{t,i,j} - v(\hat T_{i,j})) \Vert,b)\),\(b\)是outlier阈值,\(w\)是之前用于估计\(T_{i,j}\)的观测的数目。使用迭代的reweighted最小平方,我们不仅仅估计出\(\hat T_{i,j}\),也计算出在新的constraint \(T_{t,i,j}\)的inliers。在论文的后面会介绍到,我们会停止tracking一个submap,并且丢弃新计算的\(T_{t,i,j}\)如果他们不是自洽的(self-consistent)或者它与之前的估计\(T_{i,j}\)不一致。
通过这种策略实际上计算量是非常小的。因为tracking是必须做的,因此\(T_{t,i},T_{t,j}\)就会直接得到,而\(T{i,j}\)等聚合计算也是很容易做到的。
P.S.
这里的部分我看的不是很明白。应该就是将submap中多个constraint合起来优化,得到一个估计\(\hat T_{i,j}\)。但是\(v(\hat T_{i,j})\)我不是很明白这里的权重的分配。
回环检测和重定位
实际上就我来说,submap中比较难把握的部分就是回环检测了。如果不是基于关键帧的,你可能需要将所有的帧都进行相似度的度量。现在我们看看本篇论文中的回环检测。
本文中的回环检测是基于关键帧的。毕竟对所有的帧都进行回环检测是不现实的。在本篇文章中,tracking和mapping都是运行在GPU上的,而loop closure和重定位是运行在CPU上的,说明loop closure与重定位需要较少的计算量。
loop closure关键的部分在于图片的相似度衡量。本篇paper中输入只有深度图,因此对于相似度的度量不能在基于RGB图的特征匹配。它是这么做的:
对于每一个输入的深度图进行窗口采样,窗口大小为\(40 \times 30\),并且用\(\sigma = 2.5\)进行高斯滤波,得到的结果为\(\tilde D_t\)。然后使用fern conservatory来计算该图片的简化编码。在我们的实现中,每个conservatory由\(n_F=500\)个ferns组成,每个fern计算\(n_B = 4\)个二项决策。每个二项决策都根据\(\tilde D_t\)中的像素根据阈值\(\tilde D_t(x_i) < v_i\)来确定一个布尔值,这其中\(x_i,v_i\)在最开始是被随机选择的。连接一个fern中的二进制码\(f_i=\{0,1\}\)得到一个编码块\(b_j = (f_1,...,f_{n_B})\)。使用\(\ne\)操作来返回一个布尔值,通过这种方法得到一个高效的方法来计算非相似性: \[ \text{BlockHD}(\tilde D_{t_1},\tilde D_{t_2}) = \frac{1}{n_F} \sum_{j}(b_j(\tilde D_{t_1}) \ne b_j(\tilde D_{t_1})). \]
我们对所有关键帧维护这样的编码,如果某个帧与所有关键帧的最小不相似分数大于某个阈值,将它看作一个新的关键帧。
这个过程其实就是计算相似度的过程,与FlashFusion的mild类似。这部分的内容讲得也不够清楚,不清楚这样度量相似度背后的原理。不过,有很多别的闭环检测的算法,因此如果不是使用这种,我们可以跳过这一部分。下图为submap以及回环检测前和回环检测后的对比。
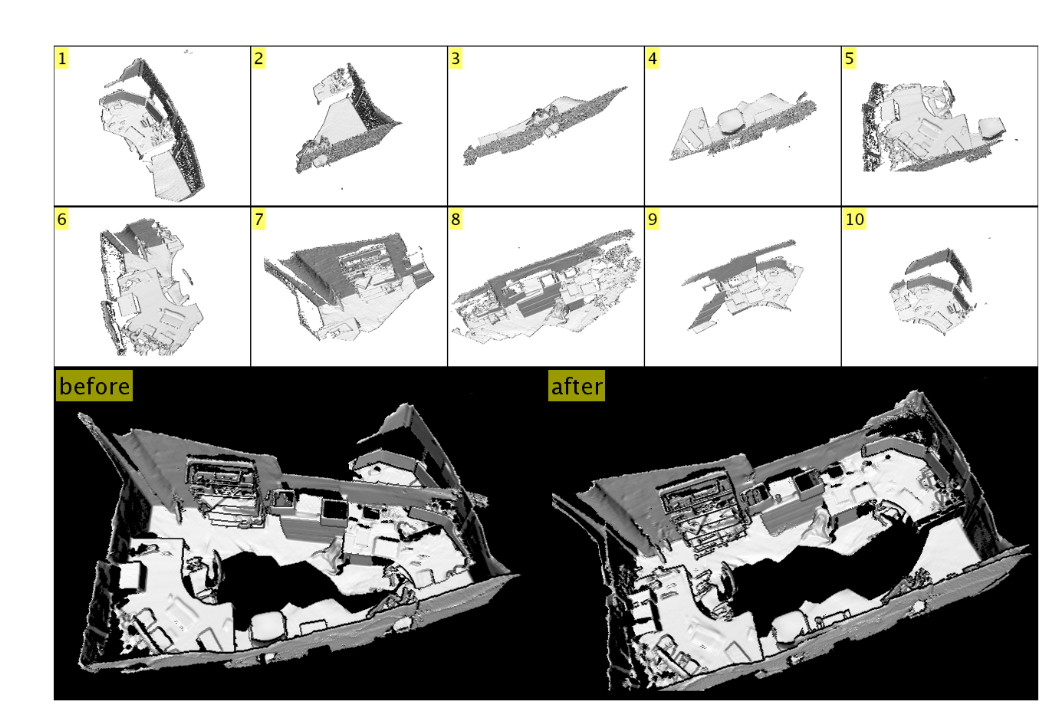
控制逻辑以及闭环验证
闭环检测过程仅仅返回关键帧的ID。它们可以很容易地联系到位姿以及submap的索引。
系统的构架图如下:
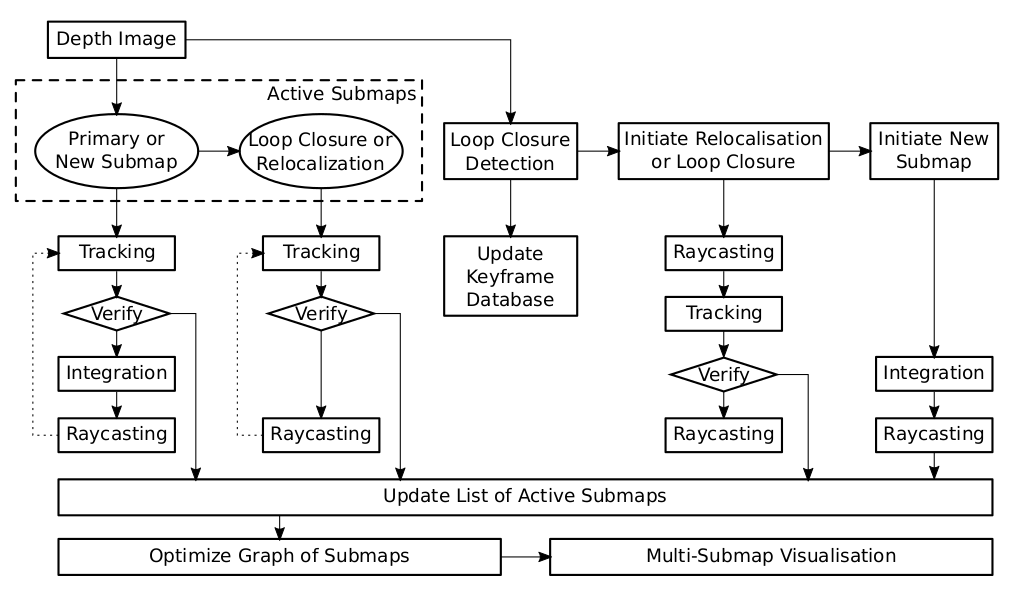
我们会一直维持一个active submaps的集合,当tracking和raycasting在所有的active submap中进行时,新的深度信息会被融合到一个主要submap。如果tracking失败了,我们就不融合这个信息,并且继续tracking这个过程。如果在任何一个submap都没有tracking成功,就丢掉。
当相机移开了主要submap的中心(由之前的submap的构造中定义的标准),我们就初始化一个新的submap。因为这个submap最开始是空的,所以需要融合深度信息用来进行raycasting和tracking。我们累积主要地图和新的地图之间的constraint,一旦得到了一个稳定的相对的位姿估计,有\(N_{stable}\)个inlier帧,则新的submap就初始化成功。
同时,闭环检测系统也在运行着。如果新进的帧对主要的场景我们有一个稳定的tracking结果,而且闭环检测结果建议插入一个关键帧,我们就更新关键帧的数据库。
另外,如果闭环检测在数据库中找到了一个相似的深度图,在之前的某个当前不活跃的submap中,我们初始化一个新的闭环attempt。意思是我们将该submap激活并且开始raycasting和tracking。因为我们试图在当前主要submap与该submap中track一序列帧,我们又能够在这两个submap之间建立constraint。我们还需要验证闭环检测,因此除了鲁棒地估计这两个submap之间的相对位姿constraint,还需要验证得到的位姿constraint的正确性。一旦我们得到了\(N_{stable}\)个inlier帧,就认为闭环检测成功,否则丢弃这个闭环检测,认为这并不是一个回环。
很明显,如果对于所有活跃的场景的tracking都失败了,我们不能建立相对位姿的constraint,而是需要重定位。在这种情况下,如果\(N_{stable}\)个tracking attemps成功了我们任务重定位成功,否则我们认为重定位失败。
在这个过程最后,我们维护一个active submap的集合,删除那些不再被track以及闭环检测和重定位失败的submap。如果有多个候选,我们通过检测submap的可见度限制来选择一个新的主要场景并且选择当前课件比例最大的submap作为主要submap。如果有新的场景或者闭环attempt成功验证了,我们会开启一个新的进程来进行图优化。图优化的结果不仅对整个过程非常重要,对之后的可视化也非常关键。
submap图优化
上面在讨论的是我们获得一系列submap之间的constraint,可以用来优化每个submap在全局坐标下的位姿。如果没有回环,那么计算确切的submap位姿是无关紧要的,而这时候全局的位姿优化问题就产生了。
用\(\tilde q(T)\)来表示四元数的三个虚分量,表示欧几里得变换\(T\)的旋转部分。用\(t(T)\)来表示平移,用\(v(T) = (\tilde q(T),t(T))^T\)将旋转和平移连接起来。如果用\(P_i\)来表示submap \(i\)的位姿,而\(T_{i,j}\)表示的是两个submap的相对constraint,那么我们想最小化的代价函数为: \[ \epsilon_{graph} = \sum_{i,j \in \mathbb T}\Vert v(P_iP_j^{-1}T_{i,j}) \Vert ^2 \]
上式中,\(mathbb T\)表示的所有的submap之间配对关系的总和。
上面的部分有点难以理解。我的理解是这样的:首先\(T_{i,j}\)是一个优化得到的submap之间的位姿转换,因为各个时刻的相同的帧在不同submap中的位姿应该是一致的,或者即使位姿不一致,它们应该也是存在一个刚性的转换。而由于噪声的存在,往往无法保证一致,因此我们会从多个对应帧中找到这两个submap之间的相对位姿。
这时候$$
而\(P_iP_j^{-1}T_{i,j}\)得到的应该是一个没有转换的向量,因此它的范数作为了优化变量。使用四元数这种表述方法是因为旋转矩阵没有转换的话是非零的,是一个单位矩阵,不便于作为代价函数。
通过上面的代价函数,我们可以得到各个submap的位姿\(P\)。
上述函数依然使用非线性优化来得到最小值。在本文中,为了方便计算,使用四元数来代表导数\(\Delta \tilde q\)。另外一个值得注意的点是海森矩阵\(\Delta ^2 \epsilon _{graph}\)或者他的估计是稀疏矩阵。对2到100个submap进行上述优化并没有显著的计算区别,建议使用稀疏和超节点矩阵因子分解方法。在实际中,这个优化仅仅偶尔会进行,而且它比较低的计算量使得它可以运行在后端的CPU线程上。
可视化
对于submap的构建实际上有多种办法,一种是SLAM中常见的,他们只是局部建立位姿和稀疏特征点的submap,而不会分割TSDF场。通过上述的SLAM再根据全局的map来建立TSDF也是可以的,但是不会减少TSDF占用的内存。另外一种是对TSDF也进行分割,visualize的时候我们可以将部分TSDF放入外存,从而减少内存占用。
本篇文章中会对TSDF也进行分割,这时候对多个submap进行可视化就需要对各个submap的TSDF进行融合。
要明白,submap的图优化和局部submap的在线更新对于实时的可视化是非常重要的。将局部submap表示为TSDF的优点在于在呈现全局映射的时候可以动态的融合各个子映射。文章中定义了一个新的TSDF: \[ \hat F(X) = \sum_{i}F_w(P_iX)F(P_iX). \]
上式中\(P_i\)为submap \(i\)的位姿,使用\(F_w\)来表示从\(F\)中取出来\(w\)项,也就是权重。可视化通过全局的TSDF,也就是\(\hat F\)来进行raycasting等等得到模型表面法向。
上面的内容就是论文的主要思路。还有一些不明白的地方可以查看原文,或者在实践中找到答案。
其实我比较疑惑的部分在于闭环检测时候,对于多个submap进行track。因为这时候序列是不同的了,因此它们的位姿也就不同,这时候又如何根据原来的帧的位姿求得\(T_{i,j}\)?
答:在submap中track得到的理论上是当前的位姿,因此在多个submap中track同一个帧一样得到的应该是相同的位姿。我之前理解错误了。注意track是得到位姿的过程。