Paper——Attention is All You Need
这次跟着李沐老师读了Transformer的原始论文:Attention is All You Need。这篇文章不长,但是构架比较新,而且一开始面对的是NLP的问题,所以其实对我来说信息量挺大的;再加上它是后面很多工作的基础,包括attention机制在视觉领域也表现得很好,所以还是专门写一篇记录一下。 ### Background
首先,正如题目所说,Transformer第一次是运用在NLP上的,NLP的输入输出是序列,例如从一段中文翻译到一段英文,这种模型被称为sequence transduction models。处理这样的模型,一般都会使用一个编码解码的架构(Encoder,Decoder)。
Encoder把输入的符号序列变成一个连续表征(向量)的序列,编码后的序列和原始序列的长度一般是一样的,这个过程可以表示为:
\[ \boldsymbol x = (x_1, \cdots, x_n) \rightarrow \boldsymbol z = (z_1, \cdots, z_n). \]
Decoder则把\(\boldsymbol z\)转化为另外一个符号序列,这个符号序列和输入不一定是等长的(例如从中英文翻译一般来说单词数和字数是不等长的):
\[ \boldsymbol z = (z_1, \cdots, z_n) \rightarrow \boldsymbol y = (y_1, \cdots, y_m). \]
我们可以认为这些序列是时间序列。这样的序列模型是auto-regressive,也就是会利用过去的值来预测,因此解码器处理当前的内容时不应该看到当前时刻之后的内容。论文中使用一个mask来屏蔽掉当前时刻后的信息。Transformer的整体构架图如下:
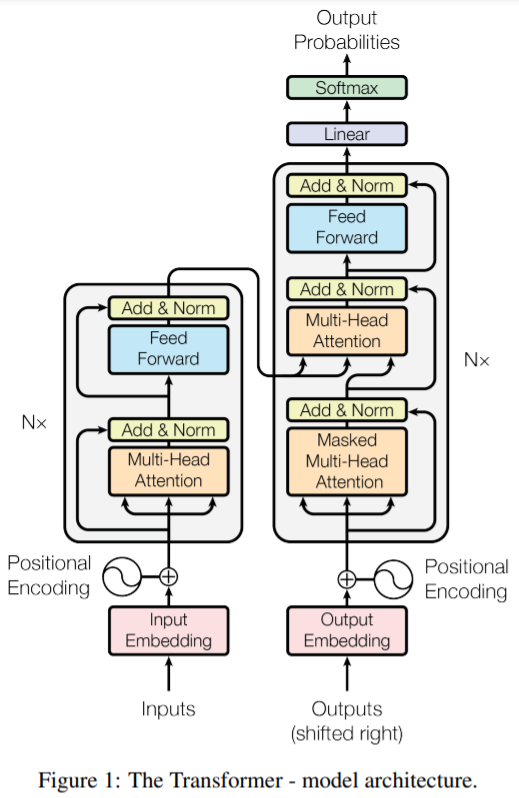
从构架看出,生成embedding的这个过程在构架图上是直接忽略掉的,直接从inputs到了input embedding,其实这里的embedding基本是和【Using the output embedding to improve language models】是一样的,而且两个生成embedding的module权重也是一样的。这幅图上还有很多看不懂的地方,不过我们后面再说(问题:Decoder这里的outputs到底是什么?应该也是symbol序列,似乎是对应的target sequence)。
Positional Encoding
从这里我们应该可以看出来,Attention是一股脑塞进去的,并不会考虑到位置的信息。而单词的前后顺序对于NLP任务来说至关重要,所以文章提出了位置编码:
\[ \begin{aligned}P E_{(p o s, 2 i)} &=\sin \left(\operatorname{pos} / 10000^{2 i / d_{\text {modcl }}}\right) \\P E_{(p o s, 2 i+1)} &=\cos \left(\operatorname{pos} / 10000^{2 i / d_{\text {model }}}\right)\end{aligned} \]
具体为何这么设计我也不是太清楚,但是神经网络是黑盒子,只要编码有区分性,就应该能学到东西。文章也提了,使用学习到的位置编码结果与上述编码几乎是一样的。最终单词的embedding就由原来的embedding加上位置编码后的向量得到了。
Attention
下面我们首先介绍一些文中提到的attention。Attention是一种操作,类似于convolution。说到attention,往往会提到Q(query),K(key)V(value)。这三个是attention的输入,一般来说也就是一组向量,attention也就是根据key来query到value的过程。在文章中,Q,K,V分别是三个矩阵,Q为\(n \times d_k\), K为\(m \times d_k\),V为\(m\times d_v\)(这里\(n\)是序列长度,\(m\)是字典的size)。当拿到\(Q\)矩阵后,我们根据其中的向量和所有的key做相似度的计算,并且根据这个相似度去计算weights,这样Q中每一个向量最后就对应了一个value的加权和。本文中相似度的计算直接使用的是向量的点乘,最终weights是将相似度输入到softmax中得到的,因此上述步骤很容易写成矩阵乘法的形式:
\[ \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \]
可以看到\(QK^T\)得到了一个\(n \times m\)矩阵,每一行是Q中的每个向量到\(m\)个key的相似度,接着经过softmax层,会输出\(n \times m\)的矩阵。因为softmax的输出天然是合为1,可以直接当作权重来使用。这里\(\frac{1}{\sqrt {d_k}}\)是一个scaling factor,主要是因为当维度\(d_k\)很大时,点乘的结果也会很大,就会把softmax函数推到梯度很小的区域。因此这里使用一个scaling factor来抵消这种影响。这个过程如下:
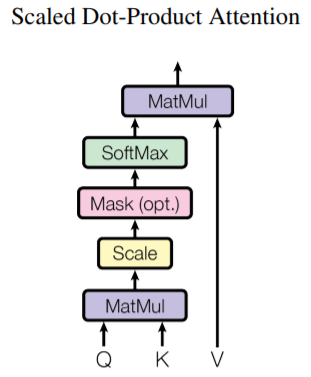
Multi-Head Attention
原始的Attention相比于Convolution的一个缺点是,convolution可以输出多个channel(也就需要多个卷积核)。而Attention本身并没有什么需要学习的参数,复制多个似乎并没有什么意义。文中提出了Multi-head Attention来达到这种效果。她的方法就是使用多个投影后的Q,K以及V,来同时进行Attention操作。具体做法如下:
\[ \begin{aligned}\operatorname{MultiHead}(Q, K, V) &=\text { Concat }\left(\operatorname{head}_{1}, \ldots, \text { head }_{\mathrm{h}}\right) W^{O} \\\text { where head }_{\mathrm{i}} &=\text { Attention }\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)\end{aligned} \]
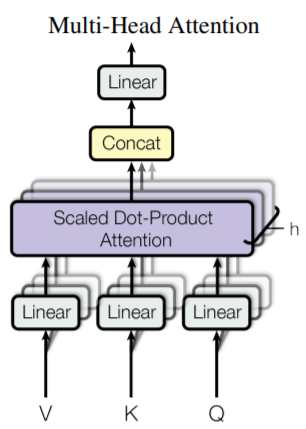
这里\(W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{V} \in \mathbb{R}^{d_{\text {model }} \times d_{v}}\)以及\(W^{O} \in \mathbb{R}^{h d_{v} \times d_{\text {model }}}\)。使用线性投影的好处就是使得输入输出的维度更加灵活。
Mask
Mask是一个和输入维度相同的binary矩阵,用来屏蔽掉一些输入。一般来说,有两个地方是需要使用mask的。
第一个是再处理的时候,会因为sequence往往是不等长的,一般的做法是使用某个默认的向量例如0来填充这些空缺,使得维度上是相等的。但是在真正处理时,我们是希望这些空缺是不起作用的,所以就会使用到mask。
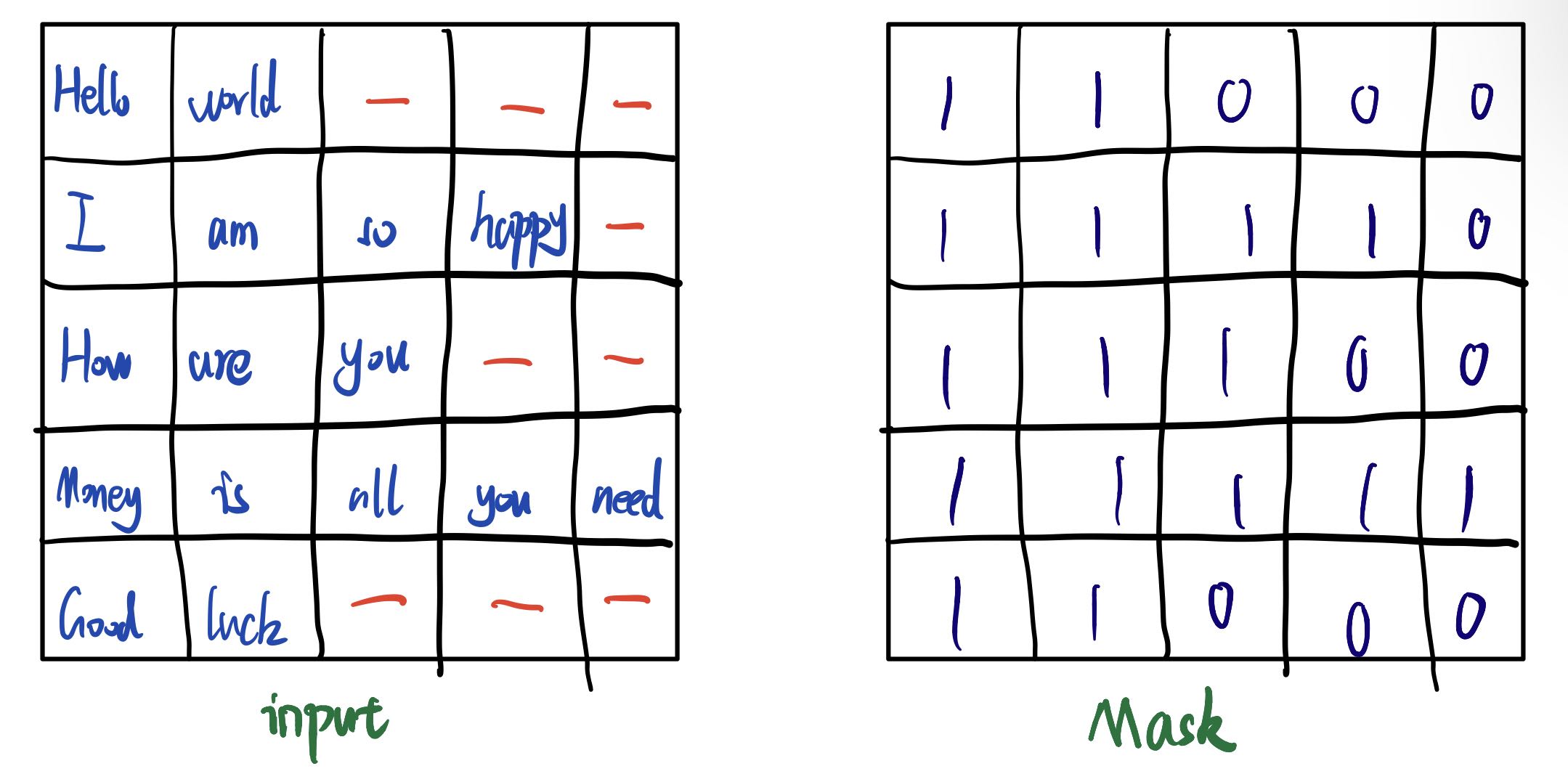
第二个情况,就是之前提到的,我们的模型是augoregressive的,每次给decoder处理时,是一个单词一个单词进行处理,而当前处理的内容不应该看到之后的内容。但是为了并行,我们是一起放进去的,所以需要一个mask来屏蔽掉之后的东西。一般来说,这样的mask是个下三角矩阵,这样对第一行,就屏蔽掉了第一个之后的内容,第二行就屏蔽掉了第二个embedding之后的内容。
Below the attention mask shows the position each tgt word (row) is allowed to look at (column). Words are blocked for attending to future words during training.

具体方法如何屏蔽呢?因为后面跟得层是softmax层,所以置零是不可取的,一般来说会置一个很大的负数,例如-1e9,这样经过softmax后的权重就等于0了。这个mask是如何使用的?具体来说,经过对target进行embedding后,我们得到了序列\(n\times d_{model}\)的矩阵(\(n\)为target sequence的长度),如果一个单词一个单词处理的话,当前的单词可以看到之前的单词,但是不能看到之后的单词,如下图:
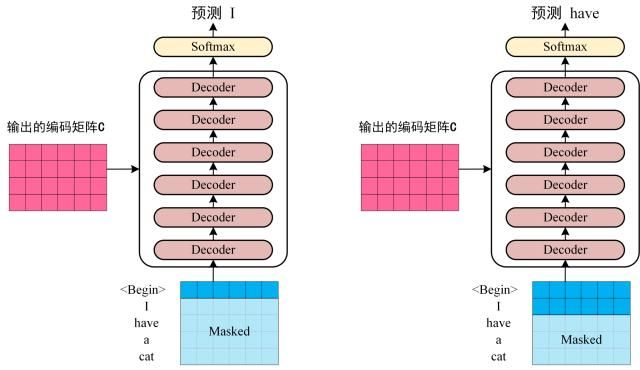
而实际中,我们会做成一个\(n \times n \times d_{model}\)的tensor,可以并行处理,因此就需要使用上述的sequence mask来去掉之后的内容。
其他
Position-wise Feed-Forward Networks
其实就是MLP:
\[ \operatorname{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} \]
Layer normalization
Layer normalization和batch normalization是不一样的。例如我们设定batch size为\(m\),feature dimension为\(n\),那么我们一个batch可以表示为\(m \times n\)的矩阵。batch normalization是看成n个样本来做normalization(每一行为一个样本),而layer normalization是看成m个样本来做normalization(每一列为一个样本)。
需要注意的是,在本文的NLP处理中,由于输入的是sequence,所以得到的并不是矩阵,而是tensor(\(m \times s \times n\) ):
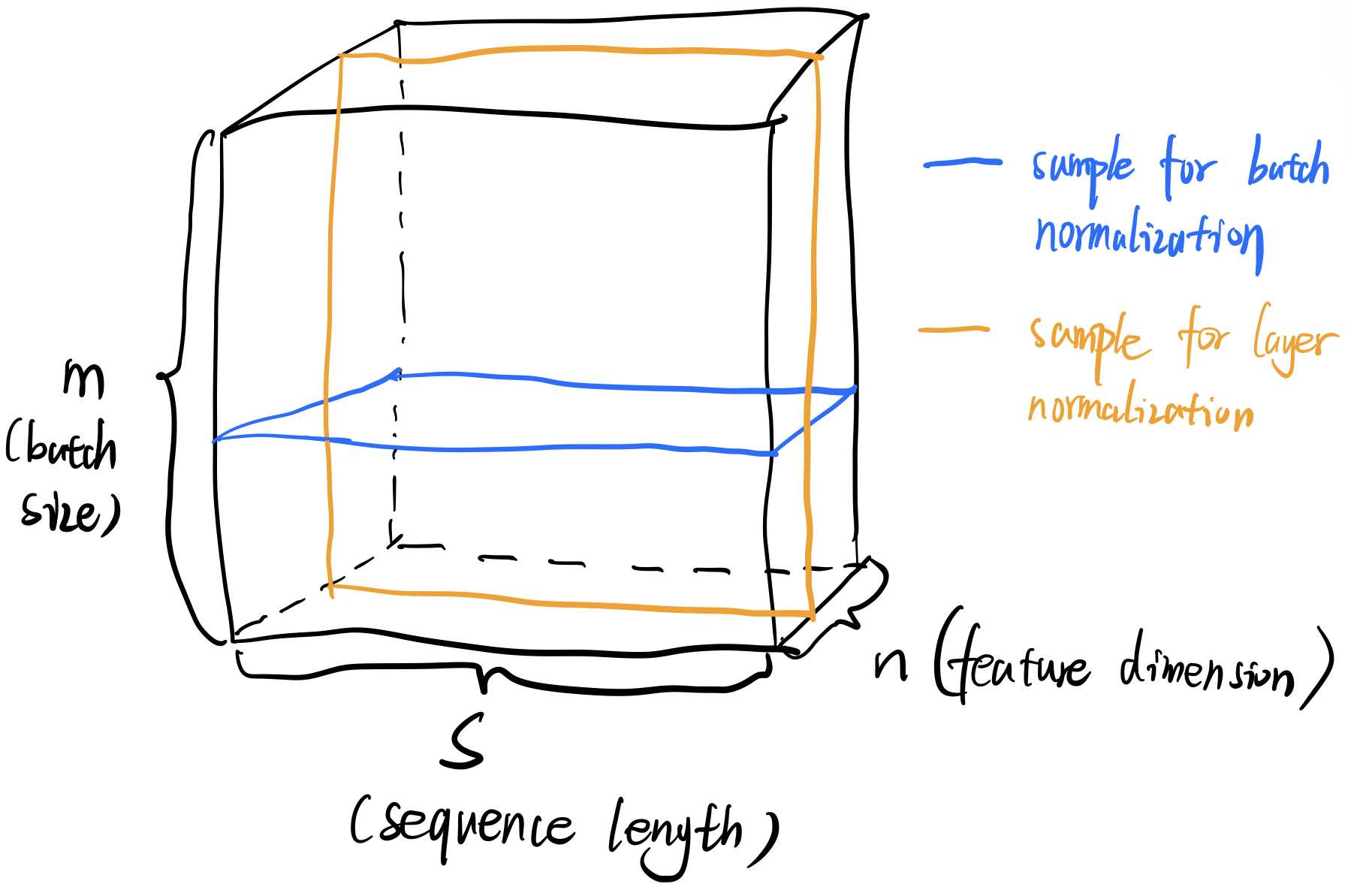
所以对应的样本的“切割”方式也不一样了。至于为什么使用layer normalization,下面一张图也许可以解释一下:

因为sequence经常是不等长的(有效部分使用阴影标出),所以很明显黄色线条看作为样本再来进行normalization是更合适的方式。
这篇文章就先介绍到这里。NLP并不是我研究的方向,但是Transformer在视觉上也表现很强,所以学习一下,后面会更新在视觉方面的改进和应用。
参考:
https://nlp.seas.harvard.edu/2018/04/03/attention.html