图形学——网格简化
上一篇博客讲了网格的相关内容,也提到了一些网格简化的算法。但是实际上网格简化是网格中很大的一个块,因此这次单独拿出一篇文章来介绍简化的相关内容。
话说到前面,网格简化有很多方法,这里介绍的多种方法,我也不是都明白,以后有机会的话会对其进行各个算法复现。对于一些复杂的算法,可能需要查阅相关论文才能明白其中的数学道理,在本文也会给出一些复杂的简化算法的论文链接。
网格简化更宽泛,具体的细节一般为层次细节简化(LOD:Level of Details)。它主要用于简化采样密集的多面体网格,以及三维场景的存储,传输和绘制。它主要目标是在不影响画面视觉效果的条件下,通过逐次简化景物的表面细节来减少场景的几何复杂度,从而提高绘制算法的效率。
在层次细节简化时候,我们会对一个原始的多面体模型建立几个不同逼近程度的几何模型。从近处观察物体,采用精细模型,从远处观察物体,采用较为粗糙的模型,当视点连续变化时,在两个不同层次的模型间会有明显的跳跃,为了追求完美应该要一个平滑的过渡,因此还需要几何形状过渡。
因此层次细节简化技术的研究主要集中在:
- 建立不同层次细节的模型。对任意给定的复杂多边形网格\(M\),由精细到粗糙建立一系列模型序列:\(M_0,M_1,…,M_n, M_0 = M\)。
- 建立相邻层次的多边形网格\(M_i,M_{i+1}\)的几何形状过渡:\(\Phi: M_i \rightarrow M_{i+1}\)。
层次细节简化第一步说到底就是不同程度的网格简化。下面介绍几个简化的基本操作,和上篇文章相似。
- 顶点删除操作L删除网格中的一个顶点,对它的相邻三角形形成的空洞做三角剖分

- 边压缩操作:网格上一条边压缩为一个顶点,与该边相邻的两个三角形退化为边
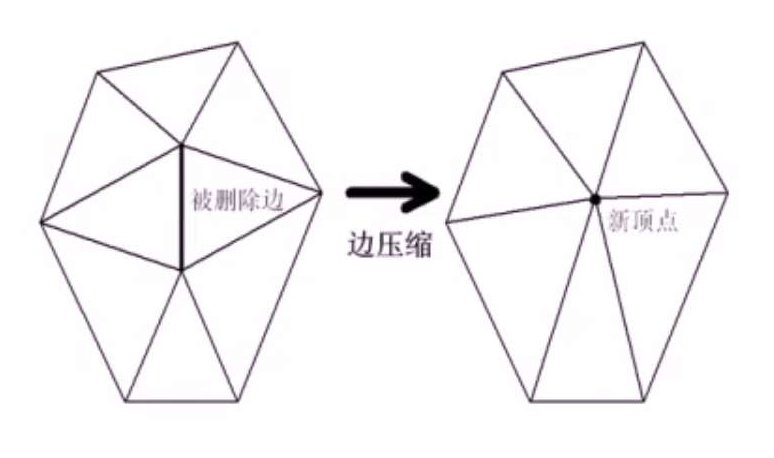
- 面片收缩操作:网格上的一个面片收缩为一个顶点,该三角形本身退化为点,其相邻的三个三角形都退化为边
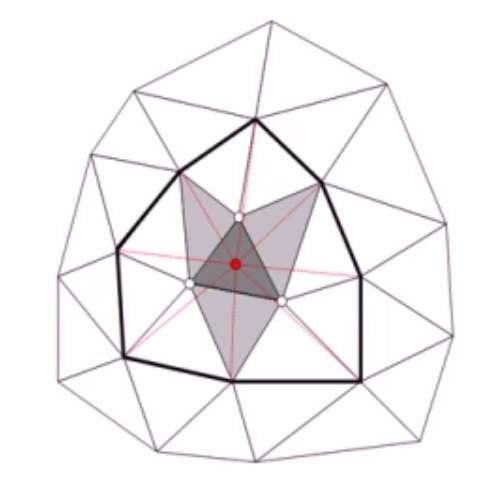
下面会介绍几个具体的算法,他们策略不同,但是最后都是上面3种操作的组合。
基于长方体滤波的多面体简化
基于长方体滤波的多面体简化是最简单的一种简化方法,它的思想是,将多个聚集在一起的顶点聚合为一个顶点,这个操作实际上是采样的一种。具体步骤如下:
- 给定一个多面体\(M\),记\(K\)为其拓扑,假设\(M\)已三角化。算法首先建立\(M\)的长方体包围盒,并将该包围盒所包围的空间均匀剖分成一系列的小长方体子空间,然后将各个子空间中的顶点聚合为一个代表顶点,如果子空间中无顶点则不考虑。一般来说聚合的这个顶点位于子空间的中心,子空间也是被均匀分割的。这些代表顶点为原多面体所示景物的重新采样。基于原多面体的拓扑结构和这些采样点可以重新产生多面体,所得多面体即为保持一定层次细节的模型。剖分的子空间越小,得到的层次模型就越逼近原多面体。
在二维空间中,长方体滤波的示意如下:

长方体滤波的主要缺点是会导致一些重要的高频细节的丢失。
下面两个算法是利用顶点删除技术的代表。顶点删除技术比较难的部分在于,删除哪些顶点?随机采样不能得到很好的效果。在网格中,近似平面的顶点可以删除,而对于尖锐部分的顶点删除后会使得模型大大折扣。因此下面介绍两个局部判别准则,用来决定删除哪些顶点比较合适。
基于相邻面片和边界的局部平坦性原则
由Schroeder提出。该判别分两种情况:
- 对于网格内部顶点\(V\),记其周围相邻面片集为\(S\),则该点的平坦性标准由下述的距离来描述:
\[d = \vert\mathbf N \cdot(v - C)
\vert\] 其中\(N\)为向量\(\frac{\sum_{f\in S}\mathbf n (f)A(f)}{\sum_{f\in
S} A(f)}\)的单位向量,\(C =
\frac{\sum_{f\in S}c(f)A(f)}{A(f)}\),这里\(A(f),c(f),\mathbf{n}(f)\)分别为三角面片的面积,中心和法向量。
这种度量方式某种程度上反映了该顶点的突出程度。 - 对于边界顶点\(v\),记与它相邻的两个边界顶点为\(v_1,v_2\),则其平坦性标准定义为\(v\)到\(v_1v_2\)连线的距离。
采用等距面来限定简化模型顶点的变化范围
由Cohen提出,这个算法相对于上述会更复杂一点。
首先介绍一个概念,叫包络(envelope)。多边形网格表面\(P\)可以看作一张分片线性参数曲面: \[ r(u,v) = (r_x(u,v),r_y(u,v),r_z(u,v)) \] 其单位法向量为: \[ \mathbf n(u,v) = (n_x(u,v), n_y(u,v),n_z(u,v)). \] 对于给定的\(\epsilon > 0\),\(P\)的三维\(\epsilon\)等距面定义为: \[ r^{\epsilon}(u,v) = r(u,v) + \epsilon \mathbf{n}(u,v) \] 近似定义原始多边形网格\(P\)沿正负发现的\(\epsilon\)等距面\(P(+\epsilon),P(- \epsilon)\)。\(\epsilon\)等距面\(P(+\epsilon)\)和\(P(-\epsilon)\)上对应顶点\(v_i^+,v_i^-\)及其法向量可表示为: \[ v_i^+ = v_i + \epsilon\mathbf{n}_i, v_i^- = v_i - \epsilon \mathbf{n}_i, \mathbf{n}_i^+ = \mathbf{n}_i^- = \mathbf{n} \] 上述方法产生的\(P_{\pm \epsilon}\)可能出现自交的现象。
我们用解析法计算\(\epsilon\)。现在来考察\(P\)上任意三角形\(\triangle v_1v_2v_3\):

对\(P\)上每个与三角形\(\triangle v_1v_2v_3\)不相邻的三角面片\(\triangle_j\),判断\(\triangle_j\)是否与\(\triangle v_1v_2v_3\)的基本柱体相交。可计算得到\(q_j\)到\(\triangle v_1v_2v_3\)的距离\(\sigma_j\)。
这两个等距面构成了表面的包络。Cohen顶点删除的过程如下:
- 利用贪婪搜索策略,将原表面\(P\)的所有顶点列入带处理的顶点队列。
- 对当前待处理顶点队列中的一顶点,算法尝试从\(P\)上删除该顶点及该顶点直接相邻的三角面片,并试图用某种类型的三角剖分法来填补顶点删除后在表面\(P\)上形成的空洞。
- 若空洞位于\(P\)的包络内且能成功地被填补,则从当前队列中删除该顶点,简化表面\(P\)模型并重构原来与该顶点相连接的各顶点的拓扑关系,否则,该顶点从当前的待处理队列中退出,表面\(P\)保持不变。上述过程知道待处理顶点队列变空为止。
这个算法的相关论文为:envelopes。
Hoppe-渐进的网格简化技术
由Hoppe提出。这个算法比较难以理解,定义了很多新的东西去讲解这个算法。在渐进网格算法中,任一网格\(\hat M\)可表示为一粗网格以及\(n\)个逐步细化网格\(M^i(i=1,…,n)\)的变换,且有\(\hat M = M^n\)。一张网格可以定义为一个二元组:\((K,V)\)。其中\(K\)是一个单纯复形(simplicical complex),它表示了\(M\)的顶点,边和面的邻接关系。
\(V = {v_i \in R^3\vert i=1,…,m}\)是\(M\)的顶点位置向量集,它定义了网格\(M\)在\(R^3\)中的形状。而单纯复形\(K\)由顶点集以及称之为单形的非空子集组成:
0-单形\(\{i\} \in K\),即为顶点,1-单形\(\{i,j\} \in K\)是一条边,2-单形\(\{i,j,k\}\in K\)为一个面。需要注意的是单纯复形\(K\)并不包含\(V\)的所有成员,只包含了构造网格\(M\)所需要的所有面,边和顶点的子集。为了在结构上刻画单纯复形,我们引进拓扑实现(topological realization)\(\vert K\vert\)的概念。
若将顶点\(\{i\}(i=1,2,…,m)\)看成为\(R^m\)中的基向量\(e_{i} = \{0,…,0,i,0,…,0\}\),则定义在\(R^m\)中的集合\(\vert K \vert\)为\(K\)的拓扑实现: \[ \vert K \vert = \bigcup_{s \ in K}\vert s\vert \] 其中\(s\)为\(K\)的一个单形,\(\vert s \vert\)为s在\(R^m\)空间中的顶点的凸包。
我们记\(\phi_v = \phi_{\vert K\vert}\),称为\(\triangle v_1v_2v_3\)在\(R^3\)中的几何实现(geometric realization)。若\(\phi_v(\vert K\vert)\)不自交,则\(\phi_v\)为1-1映射。此时,\(\phi_v\)为一嵌入映射,即对\(\forall p \in \phi_v(\vert K \vert)\),存在唯一\(m\)维向量\(b \in \vert K\vert\),使得\(p = \phi_v(b)\)。我们称\(b\)为\(p\)关于单纯复形的重心坐标向量。实际上,\(b\)可表示为: \[ b = \sum_{i=1}^mb_ie_i \] 容易知道,当\(M\)为一三角网格时,\(\phi_v(\vert K\vert)\)上任一点的重心坐标向量\(b\)中至多只有三个分量非零。
有了上述定义,Hoppe采用显示能量函数\(E(M)\)来度量简化网格与原始网格的逼近度: \[ E(M) = E_{dist}(M) + E_{spring} (M) + E_{scalar}(M) + E_{disc}(M). \] 上式中,\(E(M)\)为\(M\)的距离度量,定义为点集\(X = \{x_1,…,x_n\}\)到网格\(M\)的距离平方: \[ E_{dist}(M) = \sum_{i=1}^n d^2(x_i,\phi_v(\vert K \vert)) \] \(E_{spring}\)为\(M\)的弹性能量,这相当于在\(M\)的每条边上均匀放置一条弹性系数为\(k\)的弹簧,即: \[ E_{spring} (M) = \sum_{(i,j) \in K}k\Vert v_i,v_j \Vert^2 \] \(E_{scalar}(M)\)度量M的标量属性的精度,而\(E_{disc}(M)\)则度量了\(M\)上视觉不连续的特征线(如边界线,侧影轮廓线等)的几何精度。
Hoppe利用边收缩变换来逐步迭代计算上述能量的优化过程。下面是一个边收缩变换的例子:

因此,初始网格\(\hat M = M^n\)可经过\(n\)组的边收缩变形后简化为\(M^0\): \[ \hat M = M^n\rightarrow ... \rightarrow M^0 \] 边收缩变换的逆变换被称为顶点分裂变换,也就是将顶点分裂成一条边。
这个简化技术的过程我不是很清楚,而老师上课的时候说的也不清楚,很多符号之前并没有定义。我去查找了这篇文章,把链接放在这里,如果想要详细了解请戳:Progress Meshes
基于二次误差度量的简化技术
Hoppe的边收缩操作可推广为一般的顶点合并变换来描述\((v_1,v_2)\rightarrow v\)。而Garland和Heckbert引进了二次误差度量来刻画每一个顶点移动后引起的误差,对表面上的每一个顶点\(v_a\)均有许多三角面片与之相邻,记\(plane(v_a)\)为这些三角形所在平面所构成的集合,即: \[ plane(v_a) = \left\{(a,b,c,d)\vert ax+by+cz+d = 0,(a^2 +b^2 +c^2 =1) \text{is the coefficients of the adjacent plane of v_a} \right\} \] 我们采用如下的二次函数来度量\(v_a\)移动\(v\)时产生的误差: \[ \Delta(v_a \rightarrow v) = \sum_{p \in plane(v_a)}(pv^T)^2 \] 其中\(v = (x,y,z,1)\)为齐次坐标,展开上式可以得到: \[ \begin{aligned} \Delta(v_a \rightarrow v) &= \sum_{p \in plane(v_a)}(pv^T)^2\\ v \left(\sum_{p \in plane(v_a) K_p}\right)v^T = vQ(v_a)v^T \end{aligned} \] 式中: \[ K_p = p^Tp \begin{bmatrix} a^2 & ab &ac & ad\\ ab & b^2 &bc & bd\\ ac & bc & c^2 & cd\\ ad& bd & cd & d^2 \end{bmatrix},\\ Q(v_a) = \sum_{p \in plane(v_a)} K_p \] 这样,每一顶点\(v_a\),在预处理时,可以用上述方法计算矩阵\(Q(v_a)\),从而计算移动误差。而合并顶点每次需要移动两个顶点,因此需要考虑同时移动后形成的误差。而Garland和Heckbert简单地采用加法来刻画多点移动形成的误差,对于\((v_1,v_2) \rightarrow v\),其误差为: \[ \Delta (v) = \Delta (v_1 \rightarrow v) + \Delta (v_2 \rightarrow v) = v(Q(v_1) + Q(v_2))v^T = vQv^T。 \] 因此应该选取\(v\)使得误差达到最小。一般想法是采取优化方法如梯度下降等等,但是在这个式子里,一般\(v\)的值是有解析解的,正如线性回归一样,我们可以得到唯一解,或者伪逆技术(pseudo-inverse)求出解。如果伪逆技术失败,简单选取\(v\)为\(v_1,v_2\)或者\(\frac{v_1 + v_2}{2}\)。
二次误差度量简化算法的论文是:Surface Simplification Using Quadric Error Metrics。