Paper——Flashfusion
对于论文的阅读是我的弱项,这是导致我学习过程总是恍恍惚惚一脸懵比的一个重要的原因。出来混总是要还的。大学时候的浪荡带来的后果现在就得到了体现。
今天记录一篇对于FlashFusion的阅读。这篇文章是我们实验室的学长发在RSS的论文,是关于实时三维重建的。
FlashFusion是一个实时三维重建系统,能够在CPU上实现全局一致的稠密实时三维重建。对于文章的分析主要是对于系统构架以及具体实现的技术进行解读,因此我们跳过abstract,related work以及实验部分。
FlashFusion的系统构架图如下:
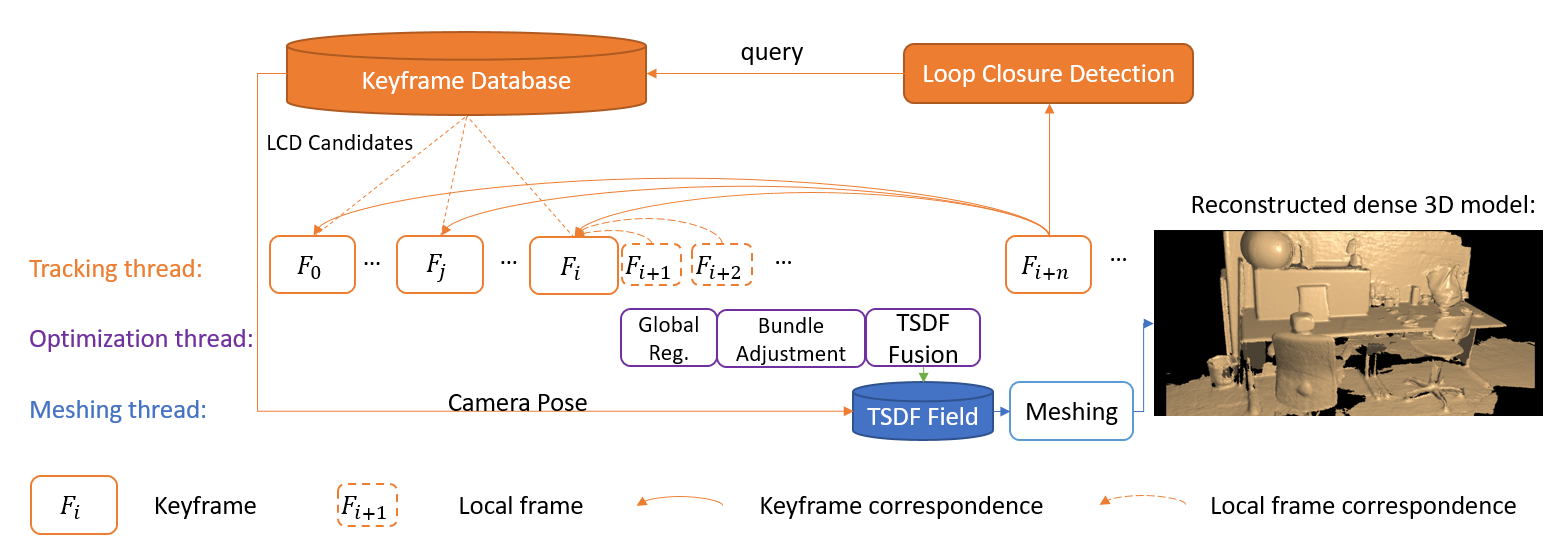
我们可以看到的是FlashFusion采取的是关键帧策略。它分为三个线程:tracking,optimization,以及meshing,分别对应了追踪,优化以及网格提取。FlashFusion之所以能实现上述效果,是因为它在回环检测,以及SLAM上都有不少的改进。
定位
FlashFusion中的SLAM部分被称为FastGO,或者GCSLAM。采取的是帧注册的策略。当捕获到新的帧时,使用MILD闭环检测与上一个关键帧进行相似度的度量,如果相似度过大,则当前帧被识别为一个新的关键帧。否则,被当作前一个关键帧对应的局部帧,并且在判断的过程中,根据ORB等特征点匹配,计算出从关键帧到当前帧的位姿变换,从而得到当前帧的位姿。
如果当前帧被识别为关键帧,则就会进行一次全局注册,对所有的关键帧的位姿进行一次优化,也就是进入了optimization线程,用于维持global consistency。为了说明这个优化过程,我们先来看看一对帧之间的代价函数: \[ \begin{equation} E_{i,j}(T_{i,j}\vert T_{i,j} \in SE(3)) = \sum_{k=0}^{\vert C_{i,j} \vert - 1}\Vert p_i^k- T_{i,j}p_j^k \Vert^2 \end{equation} \] 上式中,\(T_{i,j}\)是第i帧与第j帧之间的相对转换,\(C_{i,j} = \{(p_i^k,p_j^k)\vert k = 0,1,…,\vert C_{i,j} \vert-1\}\)是第i帧与第j帧之间的所有对应的特征点对的集合,由于有深度图,所以我们也就直接得到了特征点的相机坐标,通过转换后,属于一对的特征点坐标应当一致。因此上面的误差也算是重投影误差的一种吧。
而全局误差就是对所有的关键帧对应的局部帧上述误差的总和: \[ E(\xi) = \sum_{i=0}^{N-1}\sum_{j \in \Phi(i)} E_{i,j} = \sum_{i=0}^{N-1}\sum_{j \in \Phi(i)}\sum_{k=0}^{\vert C_{i,j} \vert-1}\Vert p_i^k - T_{i,j}p_j^k\Vert^2 \] 上式中,\(\Phi(i)\)指的是由mild选出来的最接近关键帧\(F_i\)的5个帧。如果对所有的帧都进行上述误差会使得计算量过大,使得CPU上的实现不够现实。
这5个帧是如何选出来的?实际上,当新的关键帧插入时候,会与之前所有的关键帧进行match,进而通过mild选出来5个相似度最高的关键帧,这也就意味着上述全局误差的贡献者全部为关键帧。
上述优化问题是比较好解决的,文章中使用的是高斯牛顿优化算法,根据之前的SLAM中非线性优化的章节,我们知道高斯牛顿优化需要的是:\(J(x)^TJ(x)\)与\(J(x)^Tf(x)\)。
我们将误差\(E(\xi)\)换一种写法:\(E(\xi) = r(\xi)^Tr(\xi)\),其中\(r(\xi) = [r_0^T ,r_1^T,…,r_{M-1}^T]\),\(r_l = p_i^k - T_{i,j}p_j^k\),\(M\)就是特征点对的总和了。
则在本例中,我们要求的\(\delta\),也就是每次迭代的增量为: \[ \delta = -(J(\xi)^TJ(\xi))^{-1}J(\xi)^Tr(\xi), \] 这里和高斯牛顿中推导的方法是一致的。而雅科比矩阵的求解: \[ J(\xi)^TJ(\xi) = \sum_{i=0}^{N-1}\sum_{j \in \Phi(i)}\sum_{k=0}^{\vert C_{i,j}\vert-1}(J_{i,j}^k)^TJ_{i,j}^k,\\ J(\xi)^Tr(\xi) = \sum_{i=0}^{N-1}\sum_{j \in \Phi(i)}\sum_{k=0}^{\vert C_{i,j}\vert-1}(J_{i,j}^k)^Tr_l, \] 我们不会直接求\(J(\xi)\),因为需要的是上面两个矩阵,而他们的求法甚至比直接求单独的雅科比矩阵更加容易。从FastGO中,我们可以更加详细地了解解决上面优化话题的快速算法。同时,为了提高鲁棒性,Flashfusion对于cost funstion选择了Huber norm,为了实现实时减少计算量,也不会对所有的frame pair进行计算,而是选取变化最大的10个frame pair。
这里有一个细节,在观看demo的时候,我们看到作者捂住了镜头,换到了之前扫描过的场景,而重建的视野也直接回到了之前扫描的场景。对于这个帧,插入的一定是新的关键帧,甚至有可能会tracking failed。而该帧的位姿,就是通过global optimization得到的。可以看到FlashFusion是非常强大的。
TSDF Fusion
关于TSDF的介绍,之前TSDF也提了,虽然没有涉及到具体的公式,但是还是能够有个大概的了解。下面我们用一些数学表达,介绍一下原本的TSDF的具体实现。
TSDF将空间分成若干个voxel,voxel的个数依赖于重建的分辨率,而TSDF值就是每个voxel中心距离最近的表面的距离。这个TSDF值如何得到?我们将体素根据当前的相机位姿,转换到相机坐标系下,然后投影到成像平面上。然后对于该投影坐标(二维),我们有一个对应的深度值,使用该深度值减去体素在相机坐标下的z值,我们就可以得到它到这个平面的距离。 \[ d^* = D_t(\pi(KT_tp)) - [T_tp]_z \] 上式中,\(K\)为相机内参,\(T_t\)为此刻的相机位姿,而p为体素,\(\pi\)表示从齐次到非齐次的转换,也就是取了前两维,我们通过\(D_t\)来表示取深度值,\([p]_z\)表示z轴坐标。
为了截断,我们还需要用下面这样的截断函数: \[ d = \left\{ \begin{matrix} \frac{d^ *}{d_{\max} } & \frac{d^ *}{d_{\max} }<1\\ 1&\frac{d^*}{d_{\max} }\ge 1 \end{matrix} \right. \] 其中,\(d_{\max}\)为截断值。
另外,TSDF fusion中一点是权重。因为对于不同的位姿得到的同一个voxel下的TSDF值是不同的,因此在integrate的时候需要有权重。在本篇文章中,对于sdf和权重的更新: \[ sdf_n = \frac{sdf_0 * w_0 + sdf_i * w_i}{w_i + w_0}, w_n = w_i + w_0 . \] 其中\(w_0\)为原来的,\(w_i\)为新来的,\(w_n\)为融合之后的。
我们做的重建主要是表面重建,因此关注的就是靠近表面的体素。传统的TSDF fusion会对视锥内的每一个voxel都进行上述过程,从而获取它的截断距离。而为了节省空间,研究人员提出来了Hashing和Octree两种方法,本篇文章采用的是Hash的方法。对于Hashing,每\(8\times 8\times 8\)个体素被组建成一个chunk,每个chunk都通过哈希函数映射到一个位置,大大提高了检索速度。我们可以观察一般的tsdf fusion中有效块的占比:
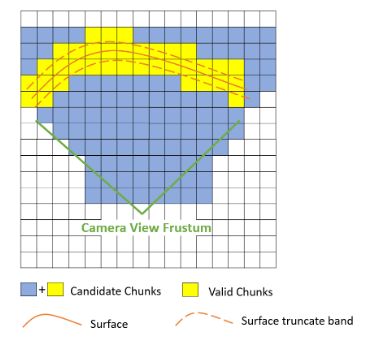
可以看到,视锥内只有一小部分的chunk包含了表面,也就是有效的TSDF值,而传统方法中对所有的voxel进行遍历得到TSDF,会浪费很多的时间和计算量。因此,FlashFusion采取了一种稀疏体素采样方法,选取有效块。对于每个chunk,计算它的8个定点的TSDF值,如果有一个定点的TSDF值(绝对值)小于某个阈值,那么将它作为有效的chunk。这背后的道理是,如果一个chunk中包含表面,它有很大的可能性至少某个面会经过这个面,有很大的可能性至少有一个顶点会投影到这个表面上,如下图:
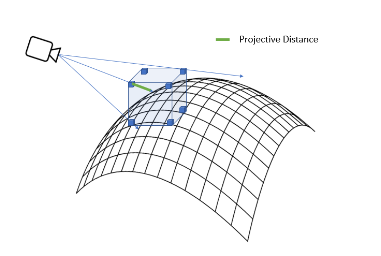
假如分辨率为\(r\),这个chunk的大小为\(N^3\)。如果一个voxel在表面的截断距离内,则:\(\vert d_v \vert \le d_{\max}\)。那么它的顶点应该会满足: \[ \vert d_c \vert\leq \vert d_v \vert + \sqrt{2}N \times r < d_{\max}+\sqrt 2N \times r. \] 因此,如果所有的顶点都大于\(d_{\max}+\sqrt 2N \times r\),那么这个chunk里几乎不可能包含表面了(这部分的内容和论文有区别,不清楚是不是论文的错误)。在实现中,论文将\(8 \times 8 \times 8\)个chunk再次归为一个Cube,现在Cube上进行稀疏采样,再在有效的Cube里进行chunk的采样。下面是采用稀疏采样的准确度和时间:
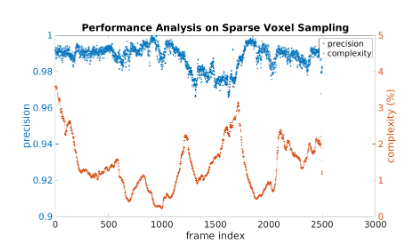
可以看到利用稀疏采样,我们可以选到98%的真正有效chunk,接着对有效的chunk进行遍历求得TSDF值,花费时间仅仅为全部体素遍历的2%。
对于有效chunk的选择仅仅应用在关键帧上,然后局部帧再被融合到对应的关键帧中。也就是,chunk的ID会被存储到对应的关键帧中,用于后面的de-integrated。对于颜色也是类似的,新的帧的颜色会给更多的权重。
需要注意的是,由于全局优化,可能各个关键帧的位姿会随时改变。这时候我们会需要deintegrate,用来在TSDF模型上减去之前的位姿的影响,而使用reintegrate,将具有新位姿的keyframe融合到TSDF模型上。
网格提取
对于网格提取可以分成多边形生成与法向提取两个部分。如何从TSDF场到一个三维网格模型,别的paper中很多又叫做raycasting,这篇文章中提到了一个方法,叫做ncrementalmarching cubes algorithm(这是一本书)。这些算法的道理都是表面两侧体素的TSDF值符号不同,因此会使用线性插值来得到表面。插值过程如下: \[ v = \frac{s_a \times v_b - s_b \times v_a}{s_a - s_b} \] 其中\(s\)为sdf值,而\(v\)代表了各个体素的坐标。你可能会奇怪,为什么sdf值和体素没有对应相乘,如果画一张图你就会理解:
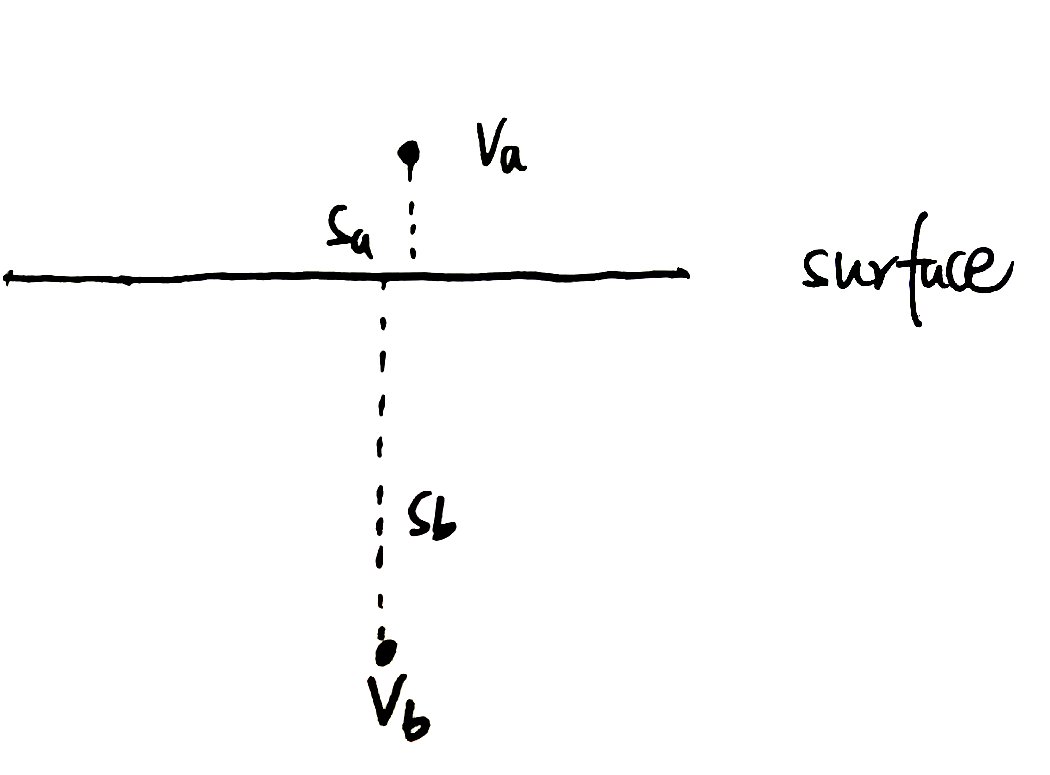
可以看到,实际上表面的点是更靠近sdf值小的,因此计算位置时候应该给sdf值小的较大的权重。
在本篇paper中,采取了动态阈值的方法,因为仅仅根据sdf值来判断是不合适的,因为如果出现比较bad的情况,比如观测的方向和表面接近平行,那么即使表面附近的voxel也有比较大的sdf值。所以基于chunk的策略,它为不同的chunk设定不同的阈值,当生成网格时,包含表面的voxel中最大的sdf被当作这个chunk的阈值。这样,当引入新的frame时,如果某个体素的sdf比这个阈值更大,就会被忽略。在这种策略下,每次meshing阶段,平均只需要增加10%的新的mesh,其他的mesh只是被更新了。通过这种方法,多边形生成的速度被加速了两倍。
法向提取的过程如下: \[ n = \begin{bmatrix} \delta_x\\ \delta_y\\ \delta_z \end{bmatrix}=\begin{bmatrix} s_{i+1,j,k} - s_{i-1,j,k}\\ s_{i,j+1,k} -s_{i,j-1,k}\\ s_{i,j,k+1} - s_{i,j,k-1} \end{bmatrix}, \] 上面的法向计算过程其实不难理解,是对该点的法向的粗略估计,需要6个临近的voxel(有效的)。在FlashFusion中,每个chunk中还维护了一个查找表,用来记录它相邻的chunk的地址,这样就避免了在多边形生成与法向提取中对总的查找表(chunkList)的查询。对于本文章中mesh的生成我了解得还不是太清楚,因为介绍的比较简单。不过这也不是我想了解的重点,因此暂时就先不深究了。
Re-integrate
reintegrate是只将关键帧对应的局部帧融合进去。对于每个关键帧,我们只融合它对应的前10个局部帧,因为如果局部帧过多,只能说明相机没有移动或者移动过慢,而这些局部帧大多提供了相似的信息,并不会有多大的贡献。因此选取前10个既保证了速度,又保证了效果。
上述就是FlashFusion的关键部分介绍。下面是一个FlashFusion重建的demo:
关于mild闭环检测和GCSlam可以看下面两篇文章: